La herramienta de cobertura de la Search Console de Google puede proporcionar información muy valiosa acerca del estado de indexación de tus páginas, pudiendo así tomar decisiones con respecto a sus contenidos. Sin embargo, en ocasiones no están demasiado claros los pasos que has de seguir para solucionar ciertos problemas.
El informe de cobertura de la consola incluye diferentes estados que te proporcionan información acerca de cómo Google está gestionando tu contenido. Todos los estados son bastante claros, indicando si las URLs procesadas son válidas o si contienen errores o advertencias. Sin embargo, existe un estado muy confuso que se da cuando Google excluye algunas de tus páginas. En concreto, cuando haces clic en alguna de estas páginas, verás que pone «Rastreada: actualmente sin indexar».
En esta guía veremos cuáles son las causas más habituales para este problema, pudiendo así solucionarlo y mejorar con ello tu posicionamiento orgánico en Google.
Contenidos
Descripción del problema
Según la documentación oficial de Google, el estado «Rastreada: actualmente sin indexar» indica que la página fue rastreada por Google, pero que todavía no la ha incluido en su índice. Esto no quiere decir que no lo vaya a hacer, ya que Google podría incluirla en el futuro, aunque en muchas ocasiones esto no sucede. De esto deducimos que:
- Google puede acceder a tu página.
- Google ha rastreado dicha página.
- Sin embargo, Google no la ha indexado tras el rastreo.
Cierto es que Google podría incluir la página en el futuro, pero si esto no ocurre, que es lo más probable, debemos intentar encontrar primero el problema antes de hallar la solución. Para empezar, si Google ha decidido excluir deliberadamente estas páginas de su índice no es porque te tenga manía, sino porque considera que son tan poco relevantes para los usuarios que no merece la pena mostrarlas en los resultados de búsqueda.
El caso es que la frustración no te dirá por qué tus páginas no están siendo indexadas. Es por ello que a continuación vamos a ver los motivos más comunes por los cuales Google decide excluir páginas de su índice. De este modo podrás identificar el problema. Además, también veremos las soluciones a dichos problemas.
Causas del problema y soluciones
A continuación veremos cada una de las causas más comunes para el problema que nos ocupa, así como una pequeña guía acerca de cómo solucionar cada uno de los casos.
Falsos positivos
Lo primero que debes hacer es inspeccionar las URLs marcadas como rastreadas pero no indexadas. En ocasiones las URLS podrían marcarse como excluidas pero aún así aparecer en el índice de Google.
Accede al buscador de Google y haz una búsqueda utilizando el operador site con la URL que está sin indexar. Para ello, basta con añadir site: justo antes de la URL absoluta a consultar:
site:https://tudominio.tld/url-excluidaEn el caso de la URL https://www.neoguias.com/accesibilidad-web podemos ver que la URL está actualmente en el índice de Google. Sin embargo, se muestra como excluida en la Search Console.
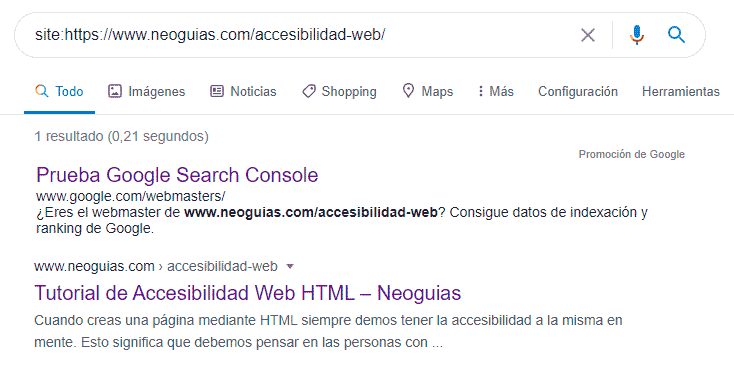
Solución: No hagas nada, todo está en orden
Si la URL se muestra en el índice de Google no hagas nada, ya que todo está en orden. Tarde o temprano aparecerá como indexada en la Search Console.
Feeds RSS
Si usas feeds RSS en tu web, seguramente se muestren como «rastreada: actualmente sin indexar» sus respectivas URLs. Estas URLs incluyen muchas veces el sufijo /feed al final de las mismas. Anque estas URLs no estén ni en tu página ni en tu sitemap, Google seguramente las haya encontrado en algún enlace de la página principal, en alguna meta etiqueta o enlazadas con el atributo rel="alternate".
Si usas WordPress, algunos plugins como All in One SEO Pack o Yoast suelen agregar tanto feeds como enlaces a los mismos automáticamente salvo que los desactives.
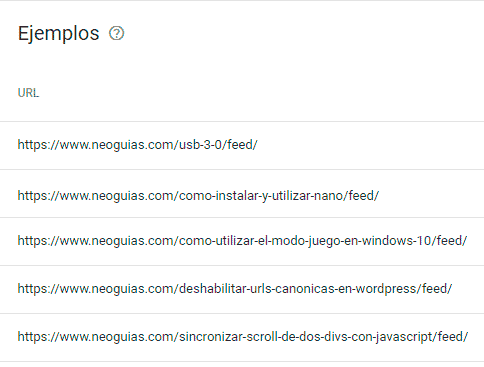
Solución: No hagas nada, todo está en orden
Google decide excluir de su índice a las URLs que contienen feeds porque no están destinadas a ser visualizadas por personas, ya que los feeds RSS contienen un documento XML que solamente resulta útil a las aplicaciones que lean o consuman dichos feeds. A continuación puedes ver un ejemplo del contenido de un feed.
<?xml version="1.0" encoding="UTF-8"?><rss version="2.0"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:atom="http://www.w3.org/2005/Atom"
xmlns:sy="http://purl.org/rss/1.0/modules/syndication/"
xmlns:georss="http://www.georss.org/georss"
xmlns:geo="http://www.w3.org/2003/01/geo/wgs84_pos#"
>
<channel>
<title>Comentarios en: Cómo instalar y utilizar el editor de texto Nano</title>
<atom:link href="https://www.neoguias.com/como-instalar-y-utilizar-nano/feed/" rel="self" type="application/rss+xml" />
<link>https://www.neoguias.com/como-instalar-y-utilizar-nano/</link>
<description>Sistemas, Aplicaciones, Dispositivos y Programación a Todos los Niveles</description>
<lastBuildDate>Mon, 27 May 2019 15:00:41 +0000</lastBuildDate>
<sy:updatePeriod>hourly</sy:updatePeriod>
<sy:updateFrequency>1</sy:updateFrequency>
<generator>https://wordpress.org/?v=5.5.3</generator>
</channel>
</rss>Tal y como puedes ver, la experiencia de usuario con estos documentos no sería demasiado positiva.
URLs con paginación
Las URLs que incluyen contenido paginado, como los índices o las listas de posts, suelen excluirse de índice de Google. Lo normal es incluir la primera página del índice, pero no el resto. Las URLs que incluyen contenido paginado suelen usar parámetros GET como ?pagina=2, ?page=3 o ?pagina=n, así como varios filtros como &categoria=tutoriales tal y como puedes ver a continuación:
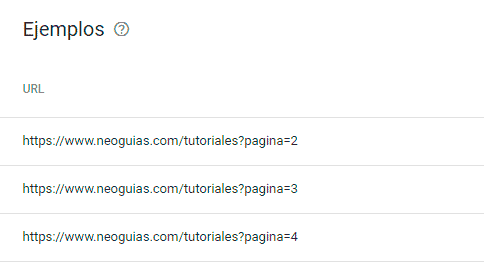
Solución: No hagas nada, todo está en orden
Google tendrá que rastrear el contenido paginado para acceder a las páginas del resto del sitio y a las categorías o elementos más profundos. Sin embargo, no necesitan estar indexadas. Debido a ello, asegúrate de que incluyes una URL canónica en estas páginas que apunten a la primera página que está paginada, antes de aplicar ningún filtro.
Para el buen funcionamiento del contenido paginado, a modo de recomendación, asegúrate de que estas páginas no están enlazadas mediante enlaces nofollow, ya que de lo contrario Google no será capaz de encontrar tu página.
Páginas no disponibles
Si Google encuentra el texto expired, sin stock o algún otro texto que indique que la página ha expirado o ya no es relevante, puede que opte por no indexarla hasta que esta situación cambie.
Esto es muy habitual en tiendas online, cuando Google identifica los sitios web como tal e intenta obtener el stock de los productos. Si se detecta que el producto al que hace referencia la página ya no está disponible, Google eliminará su respectiva página del índice. De este modo se evita que un usuario que busque un producto en Google termine en páginas que actualmente no lo venden.
Si por el contrario los productos sí están a la venta en tu web, significa que existe algún otro problema que debes solucionar, como que la etiqueta noindex esté presente en la página o algún otro problema de esta lista. Si la página no está en el índice, no tendrá la oportunidad de ganar puntos en el ranking.
Escanea el contenido visible de la página para ver si se corresponde con la realidad. Pero además, es importante que tengas en cuenta que Google no solamente se limita al contenido visible de la página, por lo que el indicador de que el producto que incluye no esté disponible podría estar oculto en el código HTML de la página.
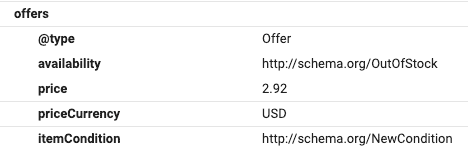
Google utiliza datos estructurados para obtener la disponibilidad de los productos. Por ello, cuando consultes el código HTML, asegúrate de que el atributo estructurado availability que indica la disponibilidad del producto realmente representa la disponibilidad actual del mismo.
Solución: Comprueba tu inventario
Si hay productos que están realmente disponibles pero cuyas URLs están excluidas por este motivo, comprueba los productos que tengan este problema con alguna herramienta como la herramienta de datos estructurados de Google. De este modo rastrearás tu página del mismo modo que Google y podrás comprobar los resultados, pudiendo así encontrar las diferencias, de haberlas. Repite este proceso con todas las URLs que tengan este problema.
Si existe un problema, seguramente esté en el código interno de tu página encargado de mostrar la disponibilidad de los productos, que seguramente sea código PHP, JavaScript, Go o Python. revísalo o contrata a alguien para que lo haga.
Poco contenido
Algunas de las páginas que se mostrarán como rastreadas pero no indexadas puede que tengan muy poco contenido. Aunque una página esté perfectamente diseñada, es posible que su contenido sea demasiado pobre, aportando un valor casi nulo a los usuarios. Aunque tú creas que la página sí aporta algo, quizás el algoritmo de Google no lo vea así, y ya sabemos quién manda aquí. Además, es posible que dichas páginas estén localizadas en algún lugar muy profundo de tu página, partiendo desde la página principal. Debido a ello, serán vistas como poco relevantes por Google.
Por ejemplo, vamos a tomar por ejemplo los siguientes resultados, de una página cuyo objetivo es el de indicar lo que dura un videojuego:
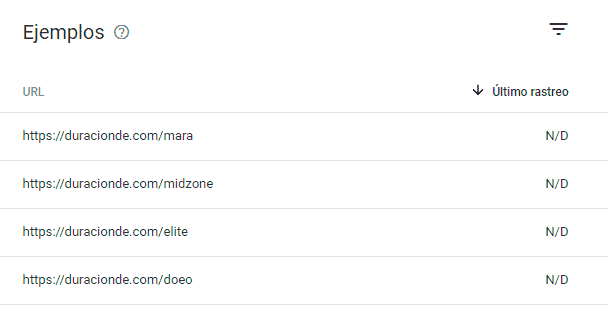
Todas las páginas de la lista anterior se muestran como rastreadas, pero Google no las ha incluido en el índice porque no disponen de datos todavía. Cuando accedemos a algunas de ellas nos encontramos con el siguiente contenido:
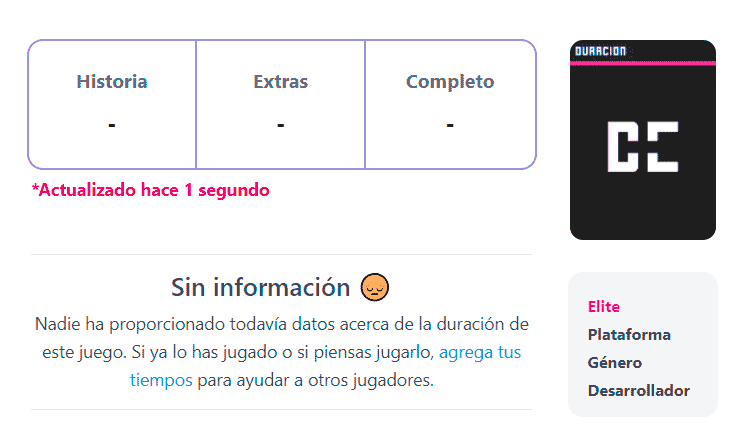
Todas estas URLs están marcadas como «Rastreada, actualmente sin indexar». Por deducción y por diferencias con las que sí incluyen contenido, asumimos que su pobre contenido es el motivo, ya que solamente incluyen un texto que se repite en todas ellas y una imagen estándar. Además, es probable que estas páginas incluyan contenido duplicado, otra mala práctica. Por ello, Google considera que estas páginas no son útiles y las excluye.
Solución: Agrega más contenido a las páginas
No todas las páginas se corresponderán con el caso de nuestro ejemplo, por lo que podría darse el caso de que quieras indexar páginas que crees que sí son relevantes. Si se da este caso, agrega más contenido a la página para que Google la indexe y además los usuarios la perciban como más útil.
Si por el contrario quieres que estas páginas sean eliminadas el índice de Google, elimínalas del sitemap, elimina los enlaces a las mismas la estructura de enlaces de tu web y agrega una meta etiqueta noindex a las mismas. También las puedes excluir mediante el archivo robots.txt. Otra opción consiste en que estas páginas devuelvan una estado 404 como respuesta.
Contenido duplicado
Este es uno de los motivos más habituales por los cuales Google podría agregar el flag de «Rastreada, actualmente sin indexar» a ciertas páginas. Si Google percibe que tu contenido está duplicado, lo rastreará pero no lo incluirá en su índice. De este modo, Google proporciona a los usuarios una gran variedad de opciones desde diferentes fuentes, no limitándose únicamente a una. En ocasiones, Google también podría marcar este contenido con el estado «Duplicado», pero no siempre se da este caso.
Este problema es muy habitual en grandes webs de comercio electrónico con productos similares, siendo habitual la duplicidad en las descripciones de los productos. Lo peor es que Google no solo podría excluir alguno de los productos de su índice, sino todos ellos.
Solución: Agrega ontenido único al contenido duplicado
Antes de nada, debes identificar si el problema real es el contenido duplicado. Para ello, debes seguir los pasos que ves a continuación:
- Accede a una de las páginas afectadas con tu navegador, copia una porción de texto que aparezca en ella y pégalo en el buscador de Google.
- Ahora agrega el parámetro
&num=100a la URL del buscador para mostrar los primeros cien resultados y haz clic en Buscar. Si tu página no aparece en la lista podría estar siendo excluída del índice de Google por tratarse de contenido duplicado, pero todavía tenemos que confirmarlo. - En el buscador, agrega ahora el parámetro
&filter=0para mostrar los resultados sin filtrar y haz clic en Buscar. Si la página aparece ahora en los resultados, tenemos un indicador bastante claro del motivo de su exclusión.
Repite el proceso anterior con todas las páginas problemáticas. Luego, sigue las recomendaciones que ves a continuación para solucionar el problema:
- Reescribe el contenido de las páginas para que sea más único. Si no dispones de tiempo suficiente, hazlo al menos con las más prioritarias.
- Utiliza propiedades dinámicas para agregar contenido único en la página, como por ejemplo widgets, elementos gráficos o información extra acerca del contenido de la misma.
- Elimina tanto contenido prediseñado de las mismas como sea posible para así eliminar el contenido duplicado y lograr que las páginas sean más únicas, reemplazando dicho contenido por contenido inherente a cada página.
- Si el contenido de tu página depende en gran medida de los usuarios que participan en ella, agrega un mensaje en el que expliques que el contenido que se escriba tendrá que ser único. Esto evitará que los usuarios usen el mismo contenido en diferentes páginas o dominios.
Siguiendo las recomendaciones que hemos visto, debería solucionarse el problema, aunque no será algo instantáneo. También puedes consultar la siguiente guía, en la que explico cómo eliminar el contenido duplicado de tu web.
Redirecciones 301
También resulta habitual encontrar las URLs con redirecciones 301 entre las páginas con el estado «Rastreada: actualmente sin indexar». Esto esto es debido a que Google rastrea las páginas que están establecidas como destino de las redirecciones, pero no las incluye en su índice. En estos casos, la URL que da origen a la redirección se indexa en su lugar.
Esto se debe a que Google podría no haber identificado todavía la redirección, por lo que puede que la perciba como duplicada en caso de que su contenido sea muy parecido.
Solución: Espera o crea un sitemap temporal
Lo normal es que Google termine reconociendo la redirección e indexando la página de destino. Sin embargo, el tiempo que tardará en hacerlo es indefinido y depende de muchos factores internos de los algoritmos de Google. Pero si esto ocurre con un gran número de URLs, quizás quieras tomar ciertas medidas para solucionar el problema lo antes posible.
Lo que puedes hacer es crear un archivo sitemap.xml temporal para acelerar el rastreo de las páginas a las que apuntan las redirecciones. En dicho sitemap temporal incluiremos las URLs de origen de las redirecciones para forzar un rastreo de Google, de modo que las elimine y agregue las páginas a las que redireccionan. Esto consolidará ambas páginas.
Contenido privado o en desarrollo
Podría darse el caso de que Google pueda tener acceso al contenido privado de tu página. Esto es habitual cuando Google tiene acceso a las URLs de las versiones en desarrollo de las páginas o aplicaciones web. Si incluye dichas versiones en su índice, tendremos un problema. Si Google no indexa este contenido, en principio todo irá bien, pero debes evitar que Google tenga acceso a las URLs que no deberían ser indexadas para que así se centre en las que sí deben indexarse, ya que Google asigna ranuras temporales limitadas de rastreo a cada sitio web.
Solución: Ajusta las prioridades de rastreo e indexación
La solución a este problema depende en gran medida del origen del mismo. En general, tu prioridad debería ser la de saber por qué vía ha obtenido acceso Google al contenido que no debería indexarse. Revisa los enlaces tu web y asegúrate de que no existen referencias ni al contenido privado ni a las posibles versiones en desarrollo de tu web. Debes eliminar las referencias para que Google perciba este contenido como poco importante o no prioritario y deje de rastrearlo.
Si tras un tiempo el problema persiste y Google sigue sin eliminar estos resultados, prueba algunas de las siguiente soluciones:
- Usa el archivo robots.txt para impedir que Google pueda acceder a dicho contenido.
- Agrega etiquetas
noindexa las versiones en desarrollo de tu web. Si usas algún framework PHP como Laravel, puedes conseguirlo agregando un middleware que agregue la etiqueta en la versión en desarrollo de tu aplicación o de tu web. - Usa etiquetas canónicas para definir cuáles son las versiones de tu web que Google debe indexar. Por ejemplo:
<link rel="canonical" href="https://www.neoguias.com/otra-pagina/" /> - Protege con una contraseña las versiones de prueba o en desarrollo de tu web.
Estás haciendo Cloaking
El cloaking es una práctica SEO considerada como Black Hat. Se da cuando un webmaster muestra una versión de sus páginas a los buscadores pero proporciona una diferente a los usuarios, camuflando la realidad. Google es capaz de detectarlo y, de darse el caso, podría no indexar tus páginas a pesar de haberlas rastreado.
En muchas ocasiones el cloaking es intencionado, pero en otras ocurre sin querer, bien porque se desconoce que hacer esto tiene un impacto negativo o porque quizás tu web haya sido hackeada, En cualquier caso, si quieres saber si tu web está haciendo cloaking, consulta el siguiente tutorial, que te ayudará a saber si tu web está haciendo cloaking.
Solución: Elimina el origen del problema
Si deduces que tu web está haciendo cloaking con algunas páginas, podrían darse dos posibles circunstancias:
- Cloaking deliberado: El cloaking es una mala práctica que debes evitar. Aunque consigas engañar a Google temporalmente, a medio plazo el resultado será negativo. Asegúrate de que la versión de tu página que muestras a Google es la misma que ven tus usuarios y, con el tiempo Google volverá a indexar las páginas afectadas.
- Han hackeado tu web: Si han hackeado tu web es posible que se muestre spam a los usuarios pero que Google siga percibiendo la versión correcta de la misma. También podría darse el caso de que ocurra lo contrario si los hackers o scripts maliciosos usan tu web para mejorar el ranking de otras páginas. Si dispones conocimientos de desarrollo web, puedes solucionar el problema por ti mismo Si el hackeo ha afectado a los servidores, necesitarás ciertos conocimientos de administración de sistemas. Disponer de una copia de seguridad te vendrá muy bien. Si usas WordPRess, consulta la siguiente guía, en la que se explica qué hacer cuando una web con WordPress es hackeada.
En resumen
Tras esta explicación ya deberías tener algo más claro el motivo por el cual Google marca algunas de tus URLs con el estado «Rastreada, actualmente sin indexar» en los informes de cobertura de rastreo. Seguramente haya otros motivos que no hemos explicado, aunque sí hemos visto los más comunes. Si el motivo es otro, consulta el tutorial en el que se explica cómo indexar una página en Google, en donde verás otras causas para este problema.
Edu Lázaro: Ingeniero técnico en informática, actualmente trabajo como desarrollador web y programador de videojuegos.


dice Agrega ontenido único al contenido duplicado falta la C
Exelente guia, me sirvio mucho.
Todo eso no es verdad. La realidad es que Google te coloca fuera del catalogo porque de esta forma espera que el dueño del sitio pague por anunciar y así aparecer en el listado de búsqueda
Yo he llegado hasta aquí para leer soluciones para mi caso, que es que no me indexa googlesearchconsole, pero además estoy pagando un poquito a googleads para empezar, y aunque empiezo a tener llamadas de clientes, aun no aparecen mis enlaces cuando busco site:miweb.
Por tanto aunque pago no aparezco en los listados de busqueda. Imagino que si aparezco de vez en cuando en resultados de busqueda en la parte de anuncios patrocinados, aunque aun no me ha aparecido eso a mi mismo. Pero ya te digo, aunque pago, no aparezco en los resultados no patrocinados.